
自定义工具
流程图
总流程图
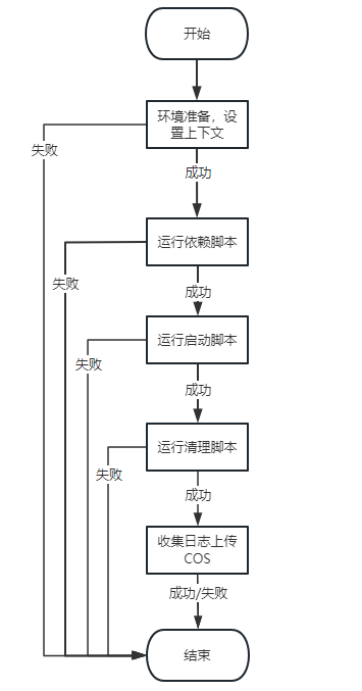
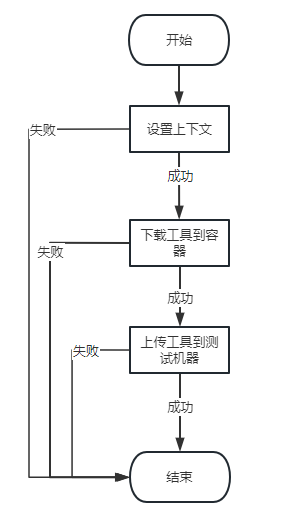
环境准备/设置上下文
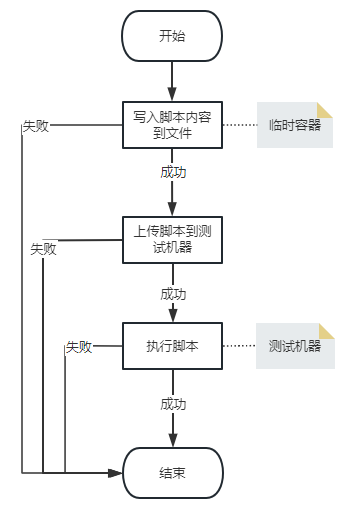
运行依赖脚本/启动脚本/清理脚本
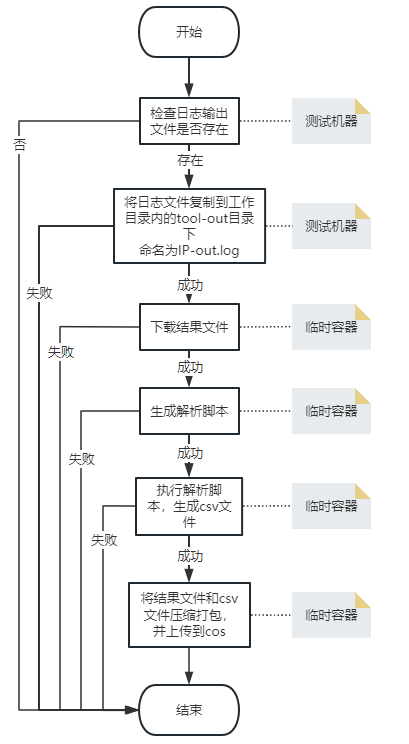
收集日志/上传COS
环境变量
我们提供了一些环境变量,以供用户在脚本中使用。
$WORKSPACE_HOME
工作目录,是程序的主要目录,用户自定义的工具包/依赖安装脚本/启动脚本,将会放在此目录下。
$CLIENT_IP
客户端IP地址。
$SERVER_IP
服务端IP地址,当工具的执行方式为“联机执行”时存在。
$TOOL_RESULT_PATH
日志输出文件所在路径。
参数说明
日志输出文件
指的是工具执行后输出的结果/日志,可写入到此日志文件中。
此路径为绝对路径,支持环境变量拼接,环境变量参考此文环境变量部分。
例如:
$WORKSPACE_HOME/out.log
执行方式
单机执行
只需一台服务器,即可完成测试任务,例如coremark/sysbench_memory/redis等。
联机执行
需要2台服务器,才可完成测试任务,例如iperf2/iperf3/mysql/nginx/mlc等。
测试工具
用户需要将测试工具打包成一个压缩包,压缩类型仅支持tar包。
程序会将压缩包进行解压,放到工作目录中,工作目录这个环境变量,可参考此文的环境变量部分。
依赖安装脚本
仅支持shell脚本,用户可用来安装测试工具或所需要的各种依赖。
支持为空,非必填。
启动脚本
仅支持shell脚本,支持用户自定义工具的启动命令。
支持为空,非必填。
用户的启动命令,需要用nohup挂到后台执行,并且在脚本最后设置退出码为0。
例如:
nohup iperf -s -i 1 -u > /dev/null 2>&1 &
exit 0
日志解析脚本
仅支持python脚本,支持用户对测试工具的测试结果文件(日志输出文件)进行解析。
支持为空,非必填。
日志解析脚本,用户需要定义2个输入参数,分别是:
1、日志输出文件的绝对路径,用户可进行读文件,然后解析。
2、csv文件的绝对路径,解析脚本最终要输出的csv文件路径。
清理脚本
仅支持shell脚本,支持用户在测试任务完成后,做一些清理操作等。
支持为空,非必填。
例子
iperf2-tcp
工具类型:
网络
日志输出文件:
$WORKSPACE_HOME/out.log
执行方式:
联机执行
服务端脚本
依赖安装脚本
rpm -ivh $WORKSPACE_HOME/iperf-2.1.6-2.el8.x86_64.rpm
exit 0
启动脚本
nohup iperf -s -i 1 > /dev/null 2>&1 &
exit 0
日志解析脚本
无
清理脚本
killall iperf
exit 0
客户端脚本
依赖安装脚本
rpm -ivh $WORKSPACE_HOME/iperf-2.1.6-2.el8.x86_64.rpm
exit 0
启动脚本
for i in {1..3}; do iperf -c $SERVER_IP -i 1 -P 1 -t 60 -f m &>> $WORKSPACE_HOME/out.log 2>&1; done
日志解析脚本
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pathlib
import re
import subprocess
import sys
iperf2_P = 1 # 要运行的并行客户端流的数量,服务器关闭之前保持的连接数。
tool_result_path = '$WORKSPACE_HOME/out.log'
iperf2_model = 'tcp_simplex' # iperf2测试模式,包括:tcp_simplex(tcp单工测试),tcp_duplex(tcp全双工测试),udp(udp测试)
def parse_tcp():
file = sys.argv[1] # 日志
output_file = sys.argv[2] # csv
pathlib.Path(file)
with open(file, "r") as f:
content = f.read()
cmd = '------------------------------------------------------------' # 匹配项
arr = content.split(cmd)
matches = re.findall(cmd, content)
count = len(matches)
even_numbers = [i for i in range(2, count + 1, 2)]
rs = []
for n in even_numbers:
last = arr[n].splitlines()[::-1]
for i in last:
if iperf2_P and iperf2_P == 1 and 'ID' not in i and ']' in i:
i = i.split(']')[1]
rs.append(re.findall(r"\d+\.?\d*", i))
break
elif 'SUM' in i:
rs.append(re.findall(r"\d+\.?\d*", i))
break
avg_list = []
for i in rs:
avg_list.append(float(i[3]))
tcp_simplex_dict = {'tcp_simplex_bandwidth': avg_list}
all_res = cal_results(tcp_simplex_dict)
res = []
for k, v in all_res.items():
item = to_item(v, k, iperf2_model)
res.append(item)
import pandas
pandas.DataFrame(res).to_csv(output_file)
return res
def to_item(value, name, model):
if 'avg' in name:
w = '平均值'
elif 'std' in name:
w = '标准差'
elif 'max' in name:
w = '最大值'
else:
w = '最小值'
if 'tcp_simplex' == model:
d = 'TCP单工'
elif 'tcp_duplex' == model:
d = 'TCP双工'
else:
d = 'UDP'
item = {
"tool": "iperf2",
"scene": f"is_client=True;model={model};test_num=1;test_time=60",
"desc": f"{d}发送带宽速率{w}",
"metric": f"iperf2_{name}",
"value": value,
"unit": "Mbps"
}
return item
def cal_results(rs):
res = dict()
import numpy as np
for key in rs:
res['{k}_avg'.format(k=key)] = round(np.average(rs[key]), 4)
res['{k}_std'.format(k=key)] = round(np.std(rs[key]), 4)
res['{k}_min'.format(k=key)] = min(rs[key])
res['{k}_max'.format(k=key)] = max(rs[key])
return res
if __name__ == '__main__':
parse_tcp()
清理脚本
无
iperf2-udp
工具类型:
网络
日志输出文件:
$WORKSPACE_HOME/out.log
执行方式:
联机执行
服务端脚本
依赖安装脚本
rpm -ivh $WORKSPACE_HOME/iperf-2.1.6-2.el8.x86_64.rpm
exit 0
启动脚本
nohup iperf -s -i 1 -u > /dev/null 2>&1 &
exit 0
日志解析脚本
无
清理脚本
killall iperf
exit 0
客户端脚本
依赖安装脚本
rpm -ivh $WORKSPACE_HOME/iperf-2.1.6-2.el8.x86_64.rpm
exit 0
启动脚本
for i in {1..3}; do iperf -c $SERVER_IP -i 1 -P 1 -t 60 -f m -u -b 1000M &>> $WORKSPACE_HOME/out.log 2>&1; done
日志解析脚本
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pathlib
import re
import subprocess
import sys
iperf2_P = 1 # 要运行的并行客户端流的数量,服务器关闭之前保持的连接数。
tool_result_path = '$WORKSPACE_HOME/out.log'
def parse_udp():
file = sys.argv[1] # 日志
output_file = sys.argv[2] # csv
pathlib.Path(file)
with open(file, "r") as f:
content = f.read()
cmd = '------------------------------------------------------------' # 匹配项
arr = content.split(cmd)
matches = re.findall(cmd, content)
count = len(matches)
even_numbers = [i for i in range(2, count + 1, 2)]
udp_res = {'udp_jitter': [], 'udp_lost_rate': [], 'udp_bandwidth': [], 'udp_pps': []}
for n in even_numbers:
tmp = _parse(arr[n])
for key in udp_res:
udp_res[key].append(tmp[key])
all_res = cal_results(udp_res)
res = []
for k, v in all_res.items():
item = to_item(v, k, 'udp')
res.append(item)
import pandas
pandas.DataFrame(res).to_csv(output_file)
return res
def _parse(out):
output = out.splitlines()
list_result = []
final_result = {
'udp_bandwidth': 0,
'udp_jitter': 0,
'udp_lost_rate': 0,
'udp_pps': 0
}
flag = 0
for i in output:
if 'Server Report' in i:
break
flag += 1
for i in range(flag, len(output)):
if len(re.findall(r"\d+\.?\d*", output[i])) == 9:
list_result.append(re.findall(r"\d+\.?\d*", output[i]))
lost = 0
my_sum = 0
for i in range(0, len(list_result)):
final_result['udp_bandwidth'] += float(list_result[i][4])
final_result['udp_jitter'] += float(list_result[i][5])
lost += float(list_result[i][6])
my_sum += float(list_result[i][7])
final_result['udp_jitter'] = final_result['udp_jitter'] / 2
if my_sum:
final_result['udp_lost_rate'] = lost / my_sum
else:
final_result['udp_lost_rate'] = 0
# pps
udp_sum_out = ""
for i in out.splitlines()[::-1]:
udp_sum_out = i
if "Sent" in udp_sum_out:
break
udp_datagrams = []
if 'Sent' in udp_sum_out:
udp_datagrams = re.findall(r"\d+\.?\d*", udp_sum_out)
if udp_datagrams:
final_result['udp_pps'] = float(udp_datagrams[-1]) / 60
return final_result
def to_item(value, name, model):
if 'avg' in name:
w = '平均值'
elif 'std' in name:
w = '标准差'
elif 'max' in name:
w = '最大值'
else:
w = '最小值'
if 'udp_bandwidth' in name:
d = '带宽速率'
unit = "Mbps"
elif 'udp_jitter' in name:
d = '传输抖动时间'
unit = "ms"
elif 'udp_lost_rate' in name:
d = '丢包率'
unit = ""
else:
d = '每秒包数'
unit = ""
item = {
"tool": "iperf2",
"scene": f"is_client=True;model={model};test_num=1;test_time=60",
"desc": f"UDP{d}{w}",
"metric": f"iperf2_{name}",
"value": value,
"unit": unit
}
return item
def cal_results(rs):
res = dict()
import numpy as np
for key in rs:
res['{k}_avg'.format(k=key)] = round(np.average(rs[key]), 4)
res['{k}_std'.format(k=key)] = round(np.std(rs[key]), 4)
res['{k}_min'.format(k=key)] = min(rs[key])
res['{k}_max'.format(k=key)] = max(rs[key])
return res
if __name__ == '__main__':
parse_udp()
清理脚本
无
coremark
工具类型:
CPU
日志输出文件:
$WORKSPACE_HOME/out.log
执行方式:
单机执行
服务端脚本
依赖安装脚本
无
启动脚本
cd $WORKSPACE_HOME/coremark-pro-main
make TARGET=linux64 XCMD='-c4' certify-all >> $TOOL_RESULT_PATH
日志解析脚本
import os
import pathlib
import sys
import pandas
TOOL_NAME = 'coremarkpro'
def parse_coremark():
file = sys.argv[1]
pathlib.Path(file)
with open(file, "r") as f:
content = f.read()
lines = content.split("\n")
keys = [
"CoreMark-PRO", "zip-test", "sha-test",
"radix2-big-64k", 'parser-125k', 'nnet_test',
"loops-all-mid-10k-sp", "linear_alg-mid-100x100-sp", "core", "cjpeg-rose7-preset"
]
res_lines = []
for line in lines:
if not line:
continue
line_parts = line.split()
l0 = line_parts[0]
if l0 in keys and len(line_parts) == 4:
res_lines.append(line)
single_fres = {}
multi_fres = {}
for line in res_lines:
single_fres.update(parse_lines(line, position=2))
multi_fres.update(parse_lines(line, position=1))
res = []
for k, v in single_fres.items():
i = to_item(k, v, is_single=True)
res.append(i)
for k, v in multi_fres.items():
i = to_item(k, v, is_single=False)
res.append(i)
pandas.DataFrame(res).to_csv(os.path.join("tool-out", "out.csv"))
return res
def parse_lines(line, position):
print("position: %s" % position)
line_mapping = {
'CoreMark-PRO': 'coremark_pro',
'zip-test': 'zip_test',
'sha-test': 'sha_test',
'radix2-big-64k': 'radix2_big_64k',
'parser-125k': 'parser_125k',
'nnet_test': 'nnet_test',
'loops-all-mid-10k-sp': 'loops_all_mid_10k_sp',
'linear_alg-mid-100x100-sp': 'linear_alg_mid_100x100_sp',
'core': 'core',
'cjpeg-rose7-preset': 'cjpeg_rose7_preset'
}
ps = line.split()
key = line.split()[0]
mkey = line_mapping.get(key)
if not mkey:
return {}
real_name = '%s%s%s' % (TOOL_NAME, "_", mkey)
return {real_name: ps[position]}
def to_item(key, value, is_single):
item = {
"tool": "coremark",
"scene": "type=SingleCore" if is_single else "type=MultiCore",
"desc": key.strip("coremarkpro_") + "程序评分",
"metric": key,
"value": value,
"unit": "iter/s"
}
if key == "coremarkpro_coremark_pro":
item["unit"] = "score"
item["desc"] = "cpu总分"
return item
parse_coremark()
清理脚本
无